BenevolentAI Investor Day Presentation Deck
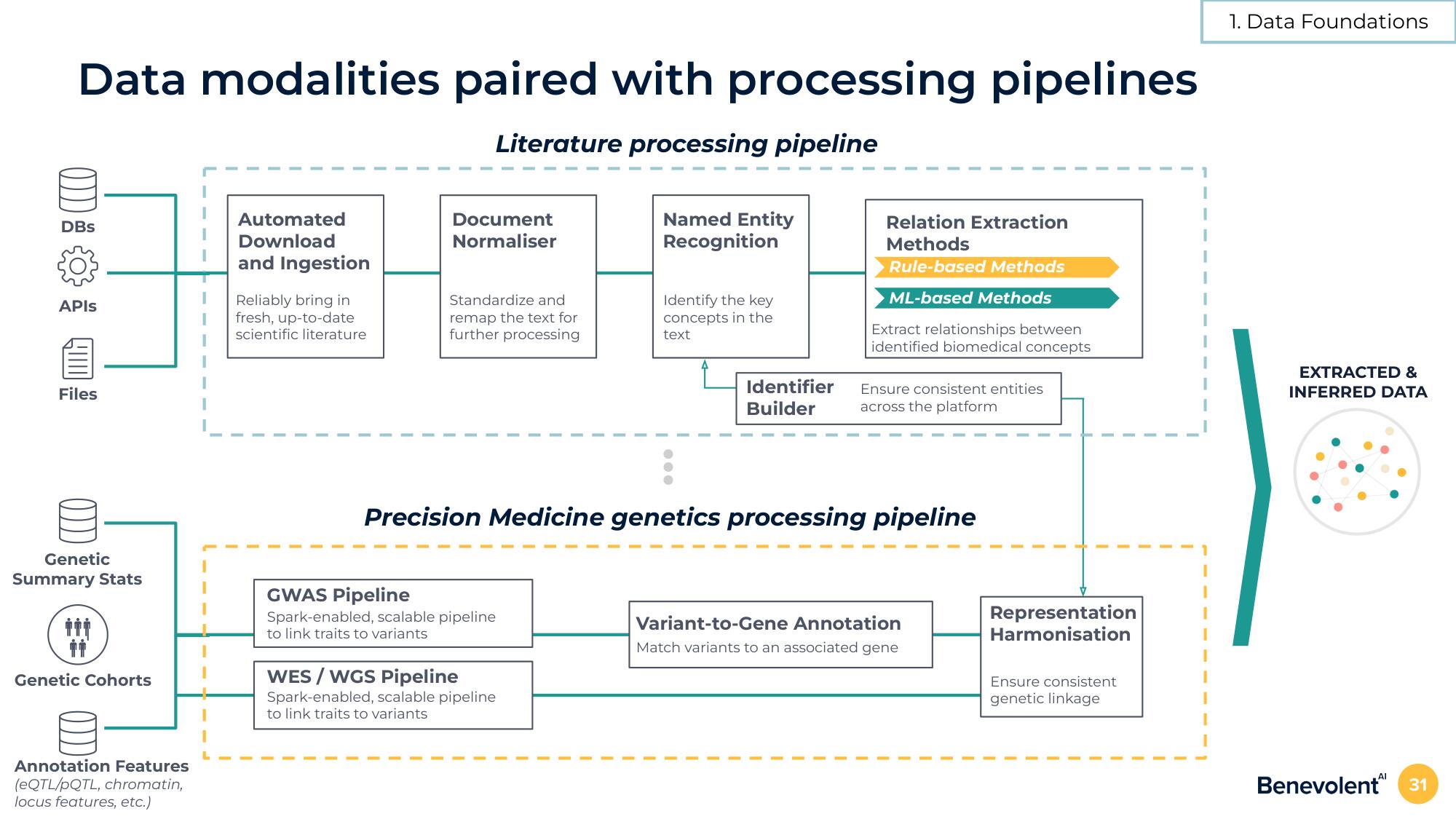
Data modalities paired with processing pipelines
Literature processing pipeline
DBs
APIs
Files
Genetic
Summary Stats
Genetic Cohorts
Annotation Features
(eQTL/pQTL, chromatin,
locus features, etc.)
Automated
Download
and Ingestion
Reliably bring in
fresh, up-to-date
scientific literature
Document
Normaliser
Standardize and
remap the text for
further processing
GWAS Pipeline
Spark-enabled, scalable pipeline
to link traits to variants
Named Entity
Recognition
WES/WGS Pipeline
Spark-enabled, scalable pipeline
to link traits to variants
Identify the key
concepts in the
text
Identifier
Builder
Relation Extraction
Methods
Rule-based Methods
ML-based Methods
Extract relationships between
identified biomedical concepts
Precision Medicine genetics processing pipeline
Ensure consistent entities
across the platform
Variant-to-Gene Annotation
Match variants to an associated gene
Representation
Harmonisation
Ensure consistent
genetic linkage
1. Data Foundations
EXTRACTED &
INFERRED DATA
Benevolent 31View entire presentation