NVIDIA Investor Presentation Deck
NVIDIA
New Tensor RT-LLM Software
More Than Doubles Inference
Performance
NVIDIA developed TensorRT-LLM, an open-source software
library that enables customers to more than double the
inference performance of their GPUs
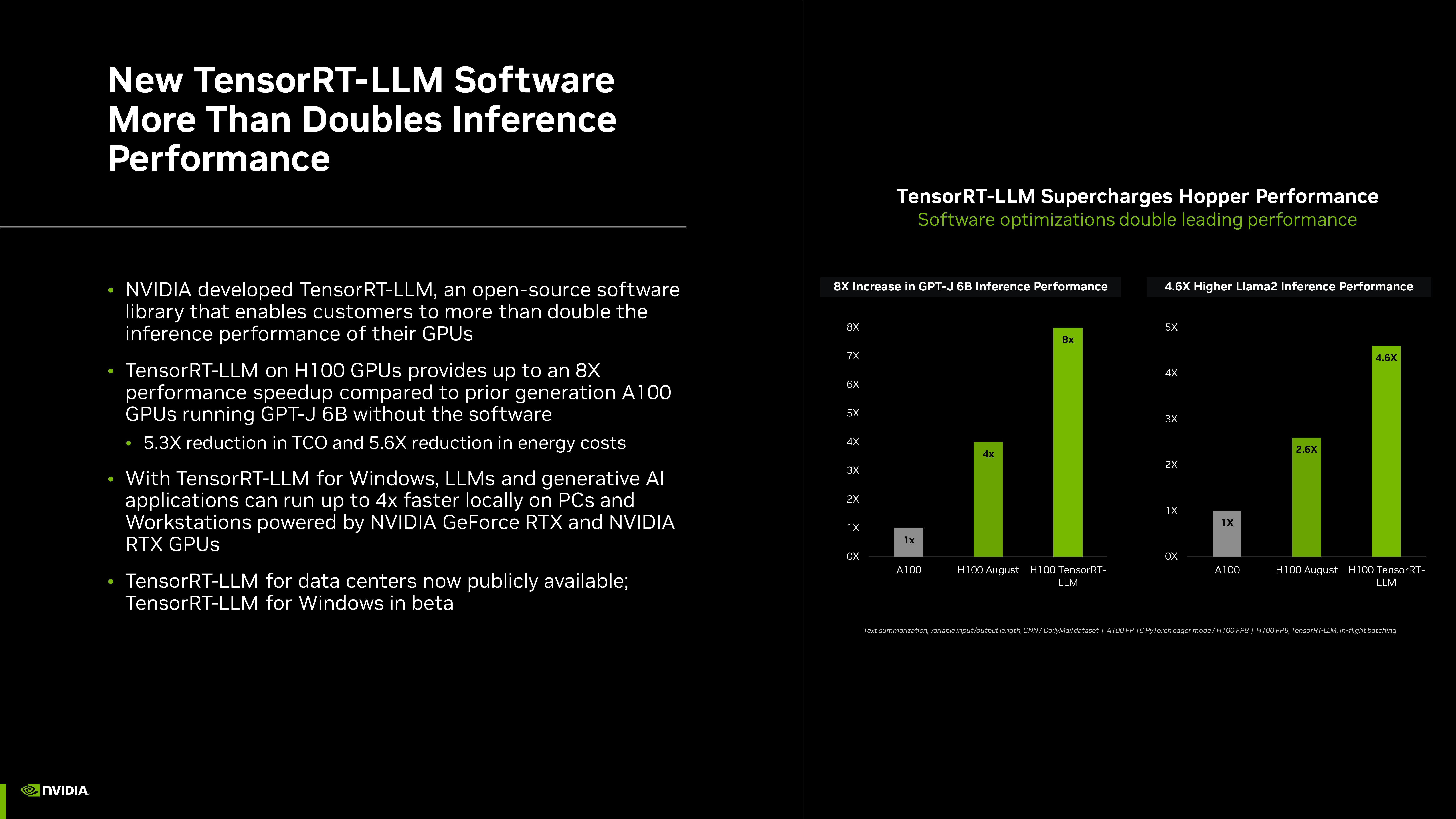
TensorRT-LLM on H100 GPUs provides up to an 8X
performance speedup compared to prior generation A100
GPUS running GPT-J 6B without the software
5.3X reduction in TCO and 5.6X reduction in energy costs
With Tensor RT-LLM for Windows, LLMs and generative Al
applications can run up to 4x faster locally on PCs and
Workstations powered by NVIDIA GeForce RTX and NVIDIA
RTX GPUs
TensorRT-LLM for data centers now publicly available;
Tensor RT-LLM for Windows in beta
8X Increase in GPT-J 6B Inference Performance
8X
7X
6X
5X
4X
3X
2X
1X
TensorRT-LLM Supercharges Hopper Performance
Software optimizations double leading performance
ох
اران
1x
A100
4x
8x
4.6X Higher Llama2 Inference Performance
H100 August H100 TensorRT-
LLM
4X
3X
2X
A100
2.6X
4.6X
H100 August H100 TensorRT-
LLM
Text summarization, variable input/output length, CNN/DailyMail dataset A100 FP 16 PyTorch eager mode/H100 FP8 | H100 FP8, TensorRT-LLM, in-flight batchingView entire presentation