NVIDIA Investor Presentation Deck
Training Compute (petaFLOPS)
10¹⁰
10⁹
108
107
106
105
104
103
10²
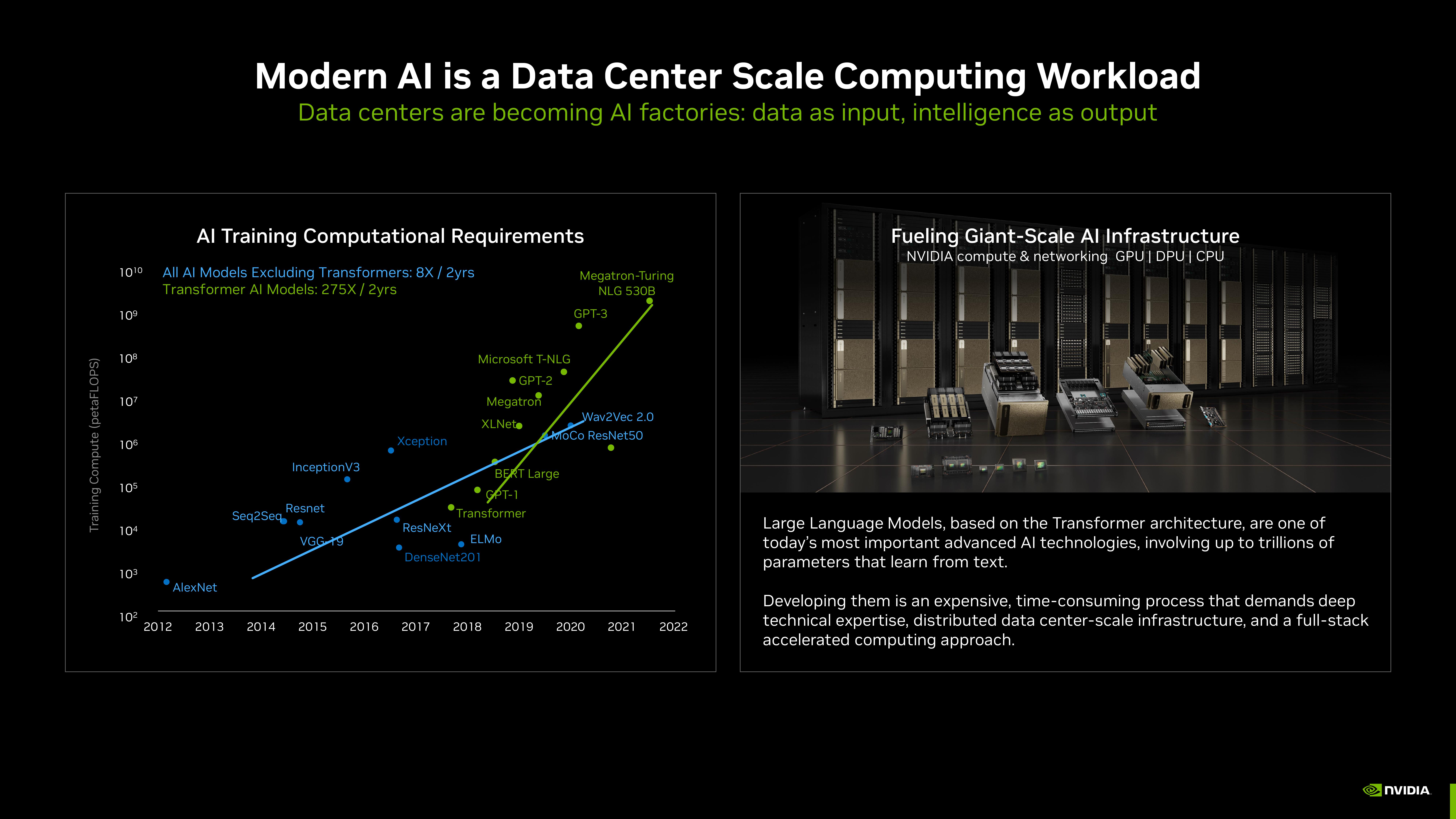
Al Training Computational Requirements
All Al Models Excluding Transformers: 8X / 2yrs
Transformer Al Models: 275X/2yrs
AlexNet
Modern Al is a Data Center Scale Computing Workload
Data centers are becoming Al factories: data as input, intelligence as output
2012
InceptionV3
Resnet
Seq2Seq
VGG19
2013 2014 2015 2016
Xception
Microsoft T-NLG
● GPT-2
ResNext
Megatron
XLNet.
GPT-1
Transformer
• ELMO
DenseNet201
BERT Large
Megatron-Turing
NLG 530B
GPT-3
Wav2Vec 2.0
MoCo ResNet50
2017 2018 2019 2020 2021 2022
Fueling Giant-Scale Al Infrastructure
NVIDIA compute & networking GPU | DPU | CPU
1998
Large Language Models, based on the Transformer architecture, are one of
today's most important advanced Al technologies, involving up to trillions of
parameters that learn from text.
Developing them is an expensive, time-consuming process that demands deep
technical expertise, distributed data center-scale infrastructure, and a full-stack
accelerated computing approach.
NVIDIA
|View entire presentation